
?")






[ad_1]
El sistema de archivos distribuido de Hadoop (HDFS) es el sistema de almacenamiento de datos principal utilizado por las aplicaciones de Hadoop. HDFS utiliza una arquitectura NameNode y DataNode para implementar un sistema de archivos distribuido que permite el acceso de alto rendimiento a los datos en clústeres Hadoop altamente escalables.
Hadoop en sí es un marco de procesamiento distribuido de código abierto que administra el procesamiento y almacenamiento de datos para aplicaciones de big data. HDFS es una parte importante de las muchas tecnologías del ecosistema de Hadoop. Proporciona un medio confiable para administrar grandes grupos de datos y admitir aplicaciones de análisis de big data relacionadas.
¿Cómo funciona HDFS?
HDFS permite la transferencia rápida de datos entre nodos informáticos. Al principio, estaba estrechamente acoplado con MapReduce, un marco de procesamiento de datos que filtra y divide el trabajo entre los nodos de un clúster. Los resultados se organizan y resumen en una respuesta coherente a una consulta. Cuando HDFS ingiere datos, la información se divide en bloques separados y se distribuye a diferentes nodos en un clúster.
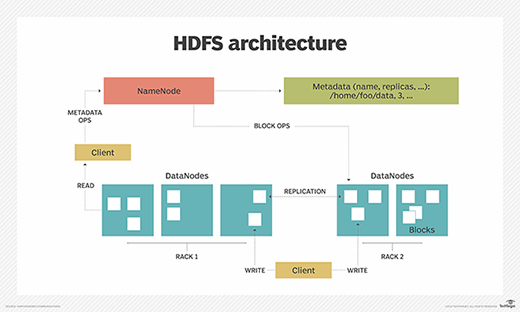
Con HDFS, los datos se escriben en el servidor una vez y luego se leen y reutilizan varias veces. HDFS tiene un NameNode primario que realiza un seguimiento de dónde se almacenan los datos de archivo en el clúster.
HDFS también tiene varios DataNodes en un clúster de hardware estándar, generalmente uno por nodo en un clúster. Los DataNodes generalmente se organizan en el mismo rack en el centro de datos. Los datos se dividen en bloques separados y se distribuyen a los distintos DataNodes para su almacenamiento. Los bloques también se replican en todos los nodos, lo que permite un procesamiento paralelo altamente eficiente.
El NameNode sabe qué DataNode contiene qué bloques y dónde se encuentran los DataNodes en el clúster de la máquina. NameNode también administra el acceso a los archivos, incluida la lectura, escritura, creación, eliminación y replicación de bloques de datos a través de DataNodes.
NameNode funciona junto con DataNodes. Como resultado, el clúster puede ajustarse dinámicamente a las necesidades de capacidad del servidor en tiempo real agregando o quitando nodos según sea necesario.
Los DataNodes están en comunicación constante con el NameNode para determinar si los DataNodes necesitan realizar ciertas tareas. Como resultado, NameNode siempre conoce el estado de cada DataNode. Si NameNode detecta que un DataNode no está funcionando correctamente, puede asignar inmediatamente la tarea de ese DataNode a otro nodo que contenga el mismo bloque de datos. Los DataNodes también se comunican entre sí, lo que les permite trabajar juntos durante las operaciones normales de archivos.
Además, el HDFS está diseñado para ser muy tolerante a fallos. El sistema de archivos replica o copia cada elemento de datos varias veces y distribuye las copias a nodos individuales, con al menos una copia almacenada en un bastidor de servidor diferente al de las otras copias.
Arquitectura HDFS, NameNodes y DataNodes
HDFS utiliza una arquitectura primaria / secundaria. El NameNode del clúster HDFS es el servidor principal que mantiene el espacio de nombres del sistema de archivos y controla el acceso del cliente a los archivos. Como componente central del sistema de archivos distribuido de Hadoop, NameNode administra y administra el espacio de nombres del sistema de archivos y proporciona a los clientes los derechos de acceso correctos. Los DataNodes del sistema administran la memoria adjunta a los nodos en los que se ejecutan.
HDFS expone un espacio de nombres del sistema de archivos y permite que los datos del usuario se almacenen en archivos. Un archivo se divide en uno o más de los bloques, que se almacenan en una serie de DataNodes. NameNode realiza operaciones de espacio de nombres del sistema de archivos, incluida la apertura, el cierre y el cambio de nombre de archivos y directorios. NameNode también regula la asignación de bloques a los DataNodes. Los DataNodes sirven solicitudes de lectura y escritura de los clientes del sistema de archivos. Además, realizan la creación, eliminación y replicación de bloques cuando NameNode les pide que lo hagan.
HDFS admite la organización de archivos jerárquica tradicional. Una aplicación o un usuario pueden crear directorios y luego guardar archivos en esos directorios. La jerarquía del espacio de nombres del sistema de archivos es similar a la mayoría de los demás sistemas de archivos. Un usuario puede crear, eliminar, cambiar el nombre o mover archivos de un directorio a otro.
El NameNode registra cualquier cambio en el espacio de nombres del sistema de archivos o sus propiedades. Una aplicación puede especificar la cantidad de réplicas de un archivo que debe administrar el HDFS. El NameNode almacena el número de copias de un archivo, conocido como factor de replicación de ese archivo.
Características de HDFS
Hay varias características que hacen que HDFS sea particularmente útil, que incluyen:
- Replicación de datos. Esto se utiliza para garantizar que los datos estén siempre disponibles y para evitar la pérdida de datos. Por ejemplo, si un nodo falla o hay una falla de hardware, los datos replicados se pueden recuperar de cualquier otro lugar en un clúster, por lo que el procesamiento continúa mientras se recuperan los datos.
- Tolerancia a fallos y fiabilidad. La capacidad de HDFS para replicar bloques de archivos y almacenarlos en nodos en un clúster grande asegura tolerancia a fallas y confiabilidad.
- Alta disponibilidad. Como se mencionó anteriormente, debido a la replicación en Notes, los datos están disponibles incluso si el NameNode o un DataNode falla.
- Escalabilidad. Debido a que HDFS almacena datos en diferentes nodos del clúster a medida que aumentan los requisitos, un clúster puede escalar a cientos de nodos.
- Alto rendimiento. Dado que HDFS almacena datos de manera distribuida, los datos se pueden procesar en paralelo en un clúster de nodos. Esto y la localidad de los datos (ver el punto siguiente) acortan el tiempo de procesamiento y permiten un alto rendimiento.
- Localidad de datos. Con HDFS, el cálculo se realiza en los DataNodes en los que se encuentran los datos, en lugar de que los datos se muevan a donde se encuentra la unidad de procesamiento. Al minimizar la distancia entre los datos y el proceso informático, este enfoque reduce la congestión de la red y aumenta el rendimiento general de un sistema.
¿Cuáles son las ventajas de HDFS?
Hay cinco beneficios principales de usar HDFS:
- Rentabilidad. Los DataNodes en los que se almacenan los datos se basan en hardware estándar económico, lo que reduce los costos de almacenamiento. Dado que HDFS es de código abierto, no hay tarifa de licencia.
- Almacenamiento de grandes cantidades de datos. HDFS almacena una amplia variedad de datos de todos los tamaños, desde megabytes hasta petabytes, y en todos los formatos, incluidos los datos estructurados y no estructurados.
- Recuperación rápida después de una falla de hardware. HDFS se desarrolló para detectar errores y corregirlos automáticamente.
- Portabilidad. HDFS es portátil en todas las plataformas de hardware y es compatible con varios sistemas operativos, incluidos Windows, Linux y Mac OS / X.
- Acceso a datos en streaming. HDFS está diseñado para un alto rendimiento de datos, que es mejor para acceder a los datos de transmisión.
Ejemplos y casos de uso de HDFS
El sistema de archivos distribuidos Hadoop se desarrolló en Yahoo como parte de la ubicación de anuncios en línea de la empresa y las necesidades de los motores de búsqueda. Al igual que otras empresas basadas en la web, Yahoo ha reunido una multitud de aplicaciones a las que han accedido cada vez más usuarios que han creado cada vez más datos.
EBay, Facebook, LinkedIn y Twitter se encuentran entre las empresas que utilizaron HDFS para ayudar en el análisis de big data para satisfacer necesidades similares a las de Yahoo.
HDFS ha encontrado un uso más allá de cumplir con los requisitos de los motores de búsqueda y la publicación de anuncios. The New York Times lo utilizó como parte de conversiones de imágenes a gran escala, Media6Degrees para el procesamiento de registros y el aprendizaje automático, LiveBet para el almacenamiento de registros y el análisis de probabilidades, Joost para el análisis de sesiones y Fox Audience Network para el análisis de registros y la minería de datos. HDFS también es el núcleo de muchos lagos de datos de código abierto.
En general, las empresas de diversas industrias utilizan HDFS para administrar grupos de big data, que incluyen:
- Compañía de electricidad. La industria energética utiliza dispositivos de medición de punteros (PMU) en sus redes de transmisión para monitorear el estado de las redes inteligentes. Estos sensores de alta velocidad miden la corriente y el voltaje en estaciones transmisoras seleccionadas de acuerdo con la amplitud y la fase. Estas empresas analizan los datos de PMU para identificar errores del sistema en los segmentos de la red y adaptar la red en consecuencia. Por ejemplo, pueden cambiar a una fuente de energía de respaldo o realizar un ajuste de carga. Las redes de PMU registran miles de registros de datos por segundo. Como resultado, las empresas de servicios públicos pueden beneficiarse de sistemas de archivos de alta disponibilidad y bajo costo, como HDFS.
- Márketing. Las campañas de marketing dirigidas dependen de que los especialistas en marketing sepan mucho sobre su público objetivo. Los especialistas en marketing pueden obtener esta información de una variedad de fuentes, incluidos los sistemas CRM, correo directo, sistemas de punto de venta, Facebook y Twitter. Dado que muchos de estos datos no están estructurados, un clúster HDFS es el lugar más barato para colocar los datos antes del análisis.
- Proveedores de petróleo y gas. Las compañías de petróleo y gas trabajan con una variedad de formatos de datos con grandes cantidades de datos, incluidos videos, modelos terrestres en 3D y datos de sensores de máquinas. Un clúster HDFS puede proporcionar una plataforma adecuada para el análisis de big data necesario.
- Investigación. El análisis de datos es una parte esencial de la investigación. Por lo tanto, los clústeres HDFS también ofrecen una forma rentable de almacenar, procesar y analizar grandes cantidades de datos aquí.
Replicación de datos HDFS
La replicación de datos es una parte importante del formato HDFS porque asegura que los datos permanezcan disponibles en caso de falla de un nodo o hardware. Como se mencionó anteriormente, los datos se dividen en fragmentos y se replican en numerosos nodos del clúster. Por lo tanto, si un nodo falla, el usuario puede acceder a los datos que estaban en ese nodo desde otras computadoras. HDFS gestiona el proceso de replicación a intervalos regulares.
¿Le gustaría aprender más sobre HDFS y Hadoop en general? Consulte nuestra guía de compra para ver algunos de estos Formas en las que se utilizan las distribuciones de Hadoop y los tipos de productos que están disponibles.
